The Unsolved Engineering Problems of AI Agents
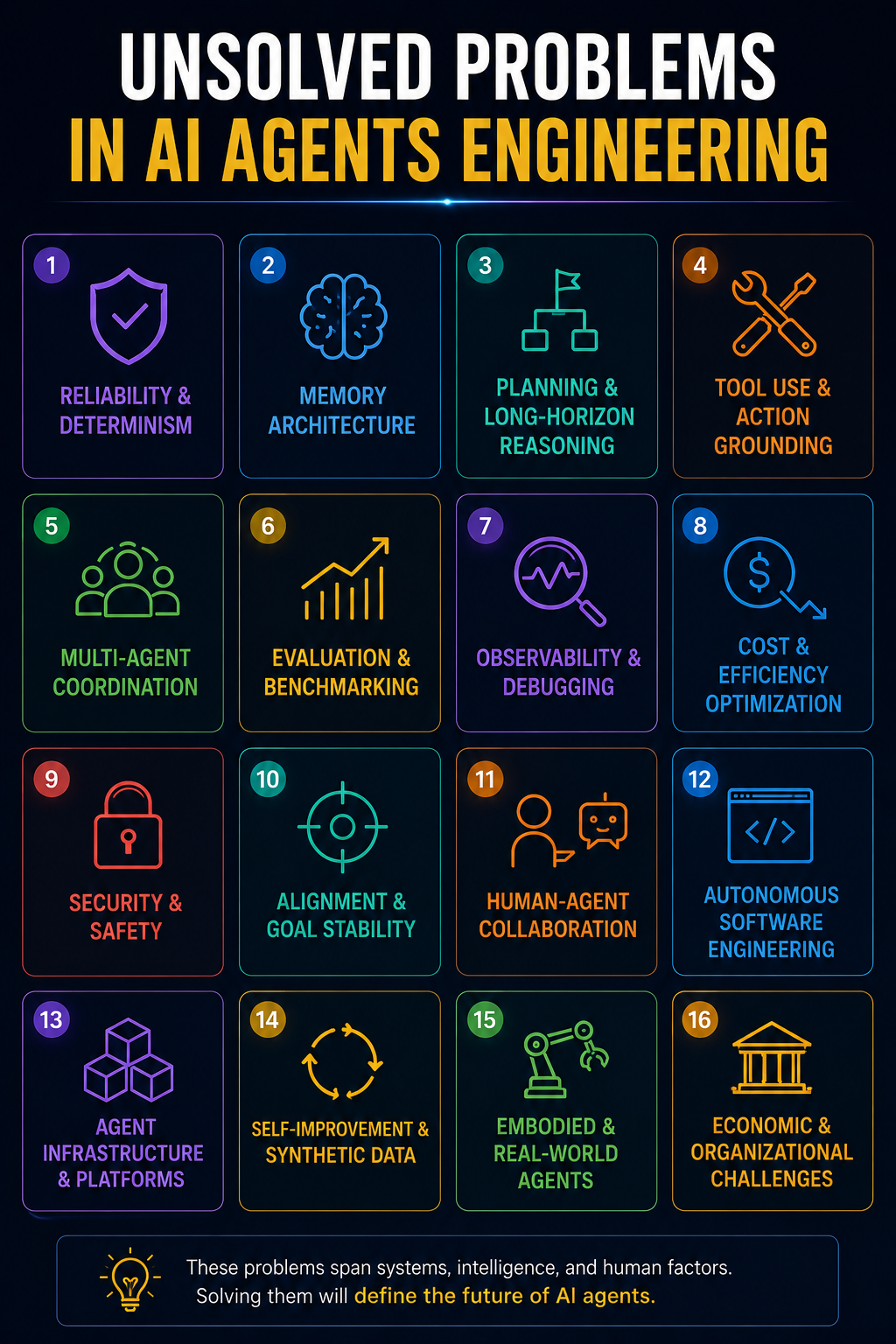
AI agents engineering is still in its “distributed systems in the 1990s” phase.
Most demos work. Very few systems are reliable, scalable, explainable, secure, cheap, and autonomous at the same time.
That gap matters. A demo can succeed once under ideal conditions. A production agent has to survive ambiguous inputs, partial failures, bad data, tool errors, cost constraints, security attacks, long-running state, and human accountability. It has to act like software while being powered by probabilistic reasoning.
Over the next five years, the field will likely evolve around a set of core unsolved engineering problems. These problems are not just model problems. They are systems problems: runtime design, memory architecture, planning, evaluation, observability, security, economics, and organizational adoption.
This is a practical roadmap of the biggest open problems in AI agents.
1. Reliability and Determinism
Reliability is the first problem because every other capability depends on it.
Agents are still non-deterministic systems pretending to be software. The same input can produce different outputs. Tool calls may succeed in one run and fail in another. A long chain can drift away from the original goal. An agent may silently hallucinate, retry the wrong operation, enter a loop, or trigger cascading failures across a multi-agent workflow.
Traditional software engineering gives us expectations: repeatability, testability, rollback, observability, and controlled side effects. Agent systems often violate all of them.
The field needs deterministic agent runtimes, transactional tool execution, state checkpointing, replay debugging, rollback systems, runtime safety constraints, and stronger guarantees around action sequencing. We need to be able to answer: given this state, this prompt, these tools, and this model configuration, why did the agent take this path?
This is where entire infrastructure categories will emerge: Kubernetes-like orchestration for agents, distributed tracing for reasoning, and transaction managers that make agent actions safer to execute in real systems.
2. Memory Architecture
Current memory systems are primitive.
Most agent memory today is vector database retrieval, chat history stuffing, or summarization. Those are useful techniques, but they are not the same as memory. Retrieval finds information. Memory changes future behavior.
A mature agent memory system needs multiple layers:
- Episodic memory: remembering experiences and prior interactions
- Semantic memory: forming durable abstractions over time
- Procedural memory: learning reusable workflows
- Working memory: managing limited context during active execution
- Shared memory: coordinating state across agents
- Memory decay: deciding what should be forgotten
- Contradiction resolution: reconciling older memories with newer evidence
The big distinction is this: RAG is retrieval, but memory is adaptation.
Future systems will likely use hierarchical memory, temporal knowledge graphs, consolidation phases, learned memory prioritization, and compression mechanisms that preserve what matters while discarding noise. The hard part is not storing more. The hard part is deciding what should influence the next action.
3. Planning and Long-Horizon Reasoning
Current agents are weak at tasks that require sustained coherence across many steps.
They can complete short workflows, but they often struggle with longer tasks that require goal decomposition, dependency tracking, dynamic replanning, recovery after failure, and resource-aware execution. After 10 or 20 steps, many agents lose context, repeat themselves, skip prerequisites, or optimize locally while damaging the global objective.
Long-horizon agents need better planning architectures. That includes recursive planning, explicit dependency graphs, subtask prioritization, progress tracking, and failure recovery. The agent should know not only what it is doing now, but why that step matters relative to the larger goal.
Several research directions are likely to matter:
- Tree search for agents: exploring possible reasoning and action paths before committing
- World models: simulating likely future outcomes internally
- Hierarchical planning: separating strategy, tactics, and execution
- Self-critique loops: evaluating plans before and during execution
The AlphaGo analogy is imperfect but useful: agents need ways to search over possible futures, not just predict the next plausible message.
4. Tool Use and Action Grounding
Many agents today are still tool wrappers.
They can call functions, browse APIs, query databases, or execute code, but they do not reliably understand the consequences of their actions. They predict text that describes actions. That is different from grounded action intelligence.
Tool use has several unsolved layers: tool discovery, tool selection, tool composition, API schema understanding, multi-tool coordination, error recovery, partial execution recovery, action verification, and side-effect awareness.
The deepest issue is causal grounding. If an agent updates a database, sends an email, merges a pull request, or purchases cloud resources, it needs to understand the state transition it is causing. It should be able to simulate likely consequences, verify execution results, and stop when the environment no longer matches its assumptions.
Future agents will need execution feedback loops that look less like “call a tool and summarize the response” and more like “plan, act, observe, verify, and revise.”
5. Multi-Agent Coordination
Multi-agent systems sound powerful, but they are currently one of the easiest ways to make an agent system slower, more expensive, and less reliable.
Most teams do not need five agents talking to each other. They need one agent with better state, better tools, and better evaluation. Multi-agent architectures become valuable only when the coordination cost is lower than the specialization benefit.
The open problems are substantial:
- How should agents communicate?
- How should shared state remain consistent?
- How do systems prevent duplicated work, loops, and deadlocks?
- When should agents split tasks?
- Can agent teams reorganize dynamically?
- How do we prevent unwanted emergent behavior?
The likely future is not simply “more agents.” It is better coordination infrastructure: agent operating systems, message buses, distributed cognition frameworks, shared-memory models, and scheduling systems that decide when parallelism is actually useful.
6. Evaluation and Benchmarking
Evaluation is still massively underdeveloped.
Current benchmarks often reward impressive demos, clean leaderboard scores, or narrow task completion. Production usefulness is harder to measure. Real agents run for long periods, use tools, interact with messy environments, recover from errors, and incur costs.
Agent evaluation needs to measure:
- Real-world task success
- Long-running workflow quality
- Autonomy level
- Reliability under repeated runs
- Tool-use correctness
- Cost-quality tradeoffs
- Safety behavior
- Multi-agent coordination quality
- Memory quality
- Recovery after failure
The future direction is continuous production evaluation. Instead of asking only “did the benchmark pass?”, teams will track failed tasks per day, recovery success rate, hallucination severity, human override frequency, cost per completed workflow, and economic value generated.
The best agent teams will treat evals as infrastructure, not as a final QA step.
7. Agent Observability
Debugging agents is still painful.
When an agent behaves unexpectedly, it is often hard to answer basic questions:
- Why did it do that?
- Which memory influenced the decision?
- Which tool failed?
- Which prompt step caused the drift?
- Which agent duplicated work?
- Which state transition made recovery impossible?
Traditional observability captures logs, metrics, and traces. Agent observability must capture reasoning traces, tool execution, memory lineage, state changes, prompt versions, intermediate decisions, and cross-agent communication.
This will become a major software category. The field needs the equivalent of Datadog or New Relic for agents: systems that make reasoning, memory, actions, and failures inspectable.
Without observability, agent engineering becomes superstition. With observability, it becomes debugging.
8. Cost Optimization
Agent systems are economically unstable when they are not carefully designed.
A simple chatbot has predictable cost. A long-running agent can explode cost through recursive context growth, repeated reasoning, redundant tool calls, inefficient retrieval, and multi-agent orchestration overhead. The system may succeed technically while failing economically.
The core cost problems are token explosion, context accumulation, repeated planning, unnecessary model calls, inefficient memory retrieval, and excessive coordination overhead.
Expected innovations include:
- Context compression: preserving useful state without carrying the full history
- Selective reasoning: using deeper reasoning only when needed
- Adaptive model routing: matching task difficulty to model capability
- Speculative execution: exploring branches in parallel when the payoff justifies it
- Cognition caching: reusing prior reasoning traces and decisions
Production agents will need cost-aware planning. The agent should understand not only “can I do this?” but “is this worth doing this way?”
9. Security
Agent security is severely underestimated.
Agents expand the attack surface because they read untrusted inputs, call tools, remember information, make decisions, and sometimes act autonomously. Traditional application security still matters, but it is not enough.
The open problems include prompt injection, tool hijacking, malicious API responses, memory poisoning, agent impersonation, accidental data exfiltration, and autonomous exploit chains.
Memory makes the security problem harder. A one-time malicious input can become a persistent corrupted belief. Tool use makes it harder again: the agent may convert a misleading instruction into a real action.
The field needs agent-native security models: permission boundaries, memory sanitization, tool authorization, provenance tracking, action approval policies, adversarial testing, and runtime containment.
Security cannot be pasted on after the agent is already autonomous. It has to be part of the runtime.
10. Alignment and Goal Stability
The deeper problem is goal stability.
Can an agent pursue a goal over a long period without drifting, shortcutting, corrupting the objective, or optimizing the wrong proxy? This becomes more important as agents gain persistent memory, self-improvement loops, and long-running autonomy.
The failure modes include goal corruption, reward hacking, shortcut behavior, misinterpreted objectives, conflicting goals, unsafe self-modification, and long-term alignment drift.
The hard question is:
How do you ensure an agent still wants what you wanted after 10,000 autonomous actions?
Short tasks can rely on human correction. Long-running agents need durable constraints, explicit objective management, interruption mechanisms, and continuous verification against the intended goal.
11. Human-Agent Collaboration
Most current systems treat humans as fallback error handlers. That is too limited.
The best future systems may not be fully autonomous agents. They may be deeply collaborative intelligence systems where humans and agents work together with clear delegation boundaries.
The open problems include trust calibration, interruptibility, human override UX, mixed-initiative workflows, shared reasoning interfaces, explainability, and escalation design.
A good collaborative agent should know when to act, when to ask, when to summarize, when to stop, and when to hand control back to the human. It should make the human more capable rather than forcing the human to supervise every fragile step.
This is where the idea of AI as a force multiplier for human intelligence becomes practical. Autonomy is not the only goal. Leverage is the goal.
12. Autonomous Software Engineering
Autonomous software engineering is still unsolved beyond medium complexity.
Coding agents can produce useful patches, write tests, explain code, and automate local tasks. But repository-scale engineering requires more than generating code. It requires architectural understanding, cross-service reasoning, regression prediction, dependency management, self-testing, PR validation, debugging, and coherence across evolving systems.
The hardest challenge is maintaining context over millions of tokens and months of change. A useful persistent coding agent would understand company architecture, remember engineering decisions, evolve with the repository, and continuously improve the system without breaking its assumptions.
The future is not just agents that write code. It is agents that understand software systems as living artifacts.
13. Agent Infrastructure
We do not yet have the equivalent of Linux, Docker, Kubernetes, or PostgreSQL for agents.
That infrastructure gap is why many teams rebuild the same scaffolding: runtimes, schedulers, tool registries, state stores, memory systems, identity layers, permission models, tracing systems, and evaluation harnesses.
The missing infrastructure layers include:
- Agent runtime: lifecycle, execution, retries, and failure handling
- Agent scheduling: priority and resource management
- Agent identity: authentication and authorization
- Agent networking: communication protocols
- Agent state storage: persistent cognition and task state
- Agent marketplaces: capability discovery and reuse
As the field matures, these pieces will become standard platforms rather than custom glue code.
14. Synthetic Data and Self-Improvement
Agents need better ways to improve themselves.
Human-generated training data is expensive and limited. Future agent systems will increasingly rely on synthetic trajectory generation, self-play environments, autonomous curriculum generation, self-evaluation, self-repair loops, and reflection systems.
The major shift is agents training agents.
That does not mean unsupervised recursive improvement without controls. It means agents generating tasks, attempting them, evaluating trajectories, identifying weaknesses, and producing better training data for future systems.
The open problem is stability. Self-improvement can amplify capability, but it can also amplify errors, biases, shortcuts, and unsafe behavior.
15. Embodied and Real-World Agents
Physical-world grounding is still primitive.
LLMs understand language patterns, not physics. Robotics and real-world autonomy require planning under uncertainty, real-time perception, sensor fusion, spatial memory, physical causality, latency constraints, and safety in environments where mistakes can be irreversible.
The gap between “describe an action” and “safely perform an action in the physical world” is enormous.
Embodied agents will need tighter integration between language models, control systems, perception models, simulators, and safety monitors. They will also need much stronger guarantees than software-only agents because their failures can affect the physical world directly.
16. Economic and Organizational Problems
The organizational problems may matter as much as the technical ones.
As agents become more capable, companies will need answers for human-agent org structures, AI-native workflows, accountability, decision ownership, governance, regulatory compliance, economic value measurement, and workforce transition.
Who owns an agent’s decision? Who reviews its work? Who is accountable when it makes a costly mistake? How do teams measure whether an agent is creating leverage or just shifting work into hidden supervision?
These questions will shape adoption. The winning systems will not only be technically impressive. They will fit into real organizations with clear accountability and measurable value.
The Likely Five-Year Evolution
The field will not mature all at once. A plausible progression looks like this:
2026: Better orchestration, better coding agents, more mature RAG systems, more reliable tool calling, and enterprise copilots.
2027: Persistent memory systems, agent observability platforms, production multi-agent workflows, and specialized agent operating systems.
2028: Long-running autonomous agents, self-improving workflows, organizational AI systems, and early economic agents.
2029: Semi-autonomous engineering teams, AI-native companies, agent marketplaces, and autonomous research agents.
2030 and beyond: Continuous autonomous software systems, agent ecosystems, self-evolving infrastructure, and human-agent hybrid organizations.
The exact timeline will be uneven. Some areas will move faster than expected, while others will hit hard reliability, safety, or economic limits. But the direction is clear: AI agents are moving from demo workflows toward infrastructure.
The Meta Problem
The deepest unsolved issue is this:
How do you build systems that can reason, act, remember, collaborate, improve, and remain aligned over extremely long time horizons under uncertainty?
That question combines operating systems, distributed systems, cognition, economics, psychology, security, software engineering, control theory, and organizational design.
AI agents engineering is becoming a new engineering discipline.
The next phase will not be won only by larger models or better prompts. It will be won by the teams that turn probabilistic intelligence into reliable systems.