Red vs. Blue: A Multi-Agent AI Ecosystem for Self-Improving Software
In the relentless pursuit of robust and secure software, developers have long relied on a combination of automated testing, manual quality assurance, and periodic security audits. But what if we could create a system that continuously and autonomously hardens software from the inside out? Inspired by military red team/blue team exercises and advancements in multi-agent AI, we can design a self-improving ecosystem where AI agents work adversarially to find and fix flaws before they ever reach production.
This article outlines a vision for a multi-agent system that pits offensive “Red Team” agents against defensive “Blue Team” agents in a perpetual cycle of attack, analysis, and improvement. The result is software that doesn’t just get tested; it evolves.
1. The Core Concept: AI-Driven Adversarial Hardening
The central idea is a self-improving multi-agent ecosystem where:
- Red Team Agents act as relentless adversaries. Their goal is to attack the software with creative test cases, sophisticated fuzzing techniques, and novel vulnerability discovery methods. They think like hackers, but work for you.
- Blue Team Agents act as diligent defenders. They defend the system by analyzing the failures uncovered by the Red Team, generating precise code fixes, and improving overall test coverage and code robustness.
- The system continuously cycles between attack and defense, leading to the progressive hardening of the software. It’s like AI-driven chaos engineering meets reinforcement learning, with humans moving from being in the loop to being on the loop—supervising and guiding the system at a high level.
2. Key Agent Roles
A successful ecosystem requires agents with specialized roles and skills.
| Agent | Purpose | Skills |
|---|---|---|
| Red Agent | Discover and create breaking test cases | Fuzzing, constraint solving, mutation, adversarial prompt crafting, exploit generation |
| Blue Agent | Propose and implement code fixes | Static analysis, patch generation, code synthesis, root cause analysis |
| Judge Agent | Evaluate results and score performance | Test pass/fail analysis, code quality metrics, security scoring, performance benchmarking |
| Coordinator Agent | Manage the workflow and ensure fairness | Task orchestration, resource allocation, state tracking, and managing the rules of engagement |
You could even introduce a Meta-Agent that observes the entire process and tunes the parameters for how aggressive each side can be, preventing stalemates and ensuring the system continues to learn.
3. The Workflow Loop: A Cycle of Continuous Improvement
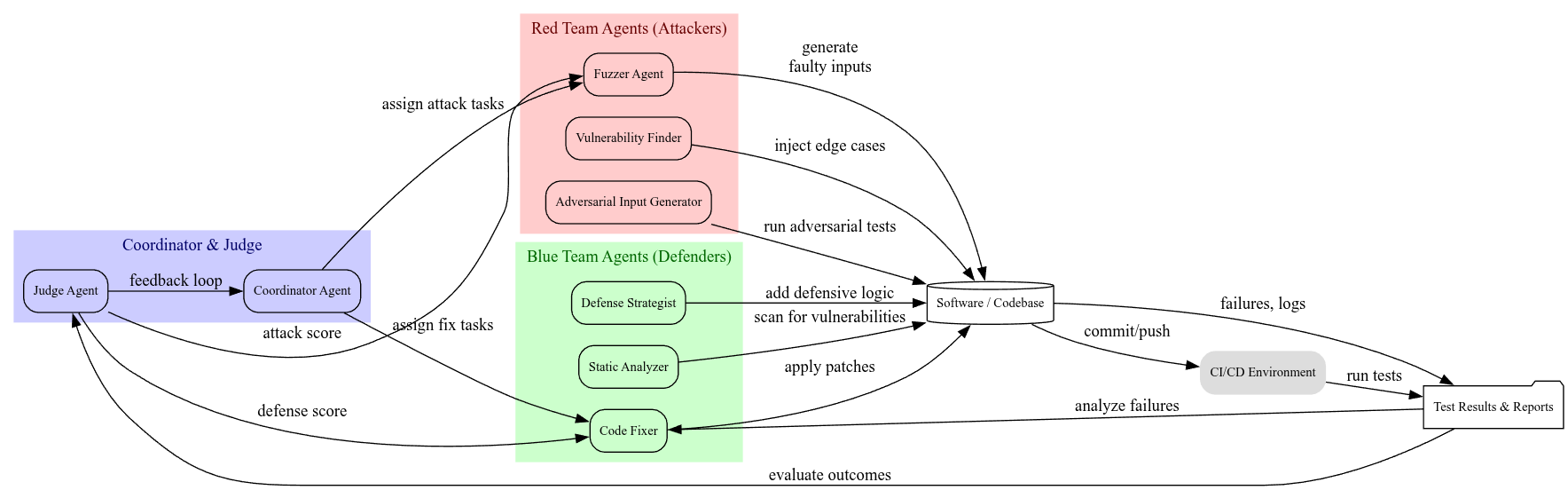
The adversarial process follows a simple yet powerful iterative loop:
- Input: The system takes a codebase or a running application as its starting point.
- Red Team Attack:
- The Red Agent generates a battery of adversarial inputs, exploits, or malformed data designed to make the system fail.
- It monitors for crashes, incorrect behavior, security vulnerabilities, or performance degradation, logging every failure meticulously.
- Blue Team Defense:
- The Blue Agent reviews the Red Team’s findings to understand the root cause of each failure.
- It then patches the code, refactors a vulnerable component, or proposes a broader architectural defense.
- The improved version of the software is submitted for re-evaluation.
- Judgment and Scoring:
- The Judge Agent re-runs all existing tests, including the new ones created by the Red Team, against the patched code.
- It scores the system on stability, performance, and security, providing a quantitative measure of improvement.
- Feedback and Evolution:
- The Red Team learns from the Blue Team’s defenses, forcing it to develop new and more sophisticated attack strategies.
- The Blue Team learns from the Red Team’s attacks, enabling it to recognize and build stronger defensive patterns.
Each cycle strengthens both teams and, by extension, the software itself. This is the principle of self-play, famously used to train AI systems like AlphaGo to achieve superhuman performance.
4. Building Intelligence: The Learning Loops
To prevent the system from stagnating, we must introduce mechanisms for autonomous evolution:
- Reinforcement Signals: Reward the Red Agent for discovering unique, critical, and effective failures. Reward the Blue Agent for creating efficient, high-quality fixes that generalize well.
- Shared Memory: Both teams should have access to a knowledge base of past attacks and defenses. This allows them to recognize patterns and avoid repeating mistakes.
- Curriculum Learning: The system should start with simple targets (e.g., unit tests for a single function) and gradually escalate to more complex challenges (e.g., integration tests, system-level security exploits).
5. How Do We Measure Success?
The effectiveness of the ecosystem can be tracked with a clear set of metrics:
- Bug Discovery Rate: The number of new, valid bugs found per iteration.
- Code Robustness Score: A composite score based on test coverage, error rate reduction, and code complexity.
- Mean Time to Patch (MTTP): How quickly the Blue Agent can fix a new vulnerability.
- Blue/Red Efficiency Ratio: A measure of how much effort the Red Team needs to find a new flaw versus how much effort the Blue Team needs to fix it.
- Adversarial Diversity: Is the Red Team generating truly novel attacks, or just variations of old ones?
6. Future Extensions
This foundational concept can be extended in several powerful ways:
- Language-Agnostic Testing: Train agents to understand the intent of the code, not just its syntax, allowing them to test applications built in any language.
- Human-in-the-Loop Review: Flag the most critical vulnerabilities or complex fixes for review by human engineers, combining the speed of AI with the wisdom of experts.
- CI/CD Integration: Embed the Red/Blue team agents directly into the CI/CD pipeline, creating a continuous adversarial guard that challenges every single commit.
- Explainable Defense Reports: Require the Blue Agent to explain why a particular fix was chosen, providing valuable documentation and insights for the development team.
7. A Simple Starting Point
You don’t need a massive, distributed system to begin experimenting with this idea. You could start small:
- Use two LLM-based agents (e.g., using a framework like CrewAI or LangGraph).
- Give them access to a codebase and a test runner (like
pytest). - Task the Red Agent with writing Python code that generates failing tests and the Blue Agent with fixing the code to make them pass.
- Use Git diffs and test runner output as the primary means of communication and state tracking.
The Red vs. Blue agent ecosystem represents a paradigm shift from periodic testing to continuous, autonomous hardening. By creating a controlled, adversarial environment, we can force software to evolve its own defenses, resulting in systems that are more resilient, secure, and reliable than ever before. The future of QA isn’t just about writing better tests—it’s about building systems that test themselves.