Measuring Massive Multitask Language Understanding: Why MMLU Matters and What It Really Tests
I remember the first time I heard about MMLU. I was reading about GPT-3’s capabilities, and there it was - this benchmark that claimed to test AI across 57 different subjects. From elementary math to professional law, from world history to computer science. It sounded almost too ambitious to be real.
But here’s the thing about MMLU (Measuring Massive Multitask Language Understanding) - it’s become one of the most important ways we measure how smart our AI systems really are. And after diving deep into it, I think it’s worth understanding what makes it special.
What Exactly Is MMLU?
MMLU is like the ultimate standardized test for AI. Imagine taking the SAT, but instead of just a few subjects, you’re tested on everything from abstract algebra to virology. That’s MMLU in a nutshell.
Created by researchers at UC Berkeley, MMLU tests language models across 57 different tasks. These aren’t random questions either - they’re carefully curated from real exams, textbooks, and academic sources. The questions range from elementary school level all the way up to professional and graduate level.
Here’s what makes it interesting: it’s all multiple choice. Four options, pick one. Simple format, but the content? That’s where it gets challenging.
Why MMLU Became So Important
Before MMLU, we had plenty of AI benchmarks. But most focused on specific skills - reading comprehension, math problems, or common sense reasoning. MMLU was different. It asked a simple but profound question: “How well can an AI system perform across the breadth of human knowledge?”
This matters because real intelligence isn’t just about being great at one thing. It’s about being adaptable, drawing connections across domains, and applying knowledge in different contexts. MMLU tries to measure that.
Let Me Show You Some Real Examples
To really understand MMLU, let’s look at some actual questions from different subjects:
Elementary Mathematics: What is the value of 5 × 6 + 3?
- A) 28
- B) 33
- C) 38
- D) 43
High School Psychology: According to Piaget’s theory of cognitive development, which stage is characterized by the development of abstract thinking?
- A) Sensorimotor
- B) Preoperational
- C) Concrete operational
- D) Formal operational
Professional Law: Under the doctrine of respondeat superior, an employer is liable for an employee’s tortious conduct if:
- A) The employee was acting within the scope of employment
- B) The employer was negligent in hiring the employee
- C) The employee intended to benefit the employer
- D) All of the above
College Computer Science: In object-oriented programming, which concept allows a class to inherit properties and methods from another class?
- A) Encapsulation
- B) Polymorphism
- C) Inheritance
- D) Abstraction
See the range? From basic arithmetic to complex legal principles. This is what makes MMLU both fascinating and challenging.
The Four Categories That Matter
MMLU organizes its 57 subjects into four main areas:
1. STEM (Science, Technology, Engineering, Math) This includes everything from basic math to advanced physics, chemistry, and computer science. It’s where most AI systems struggle the most, especially with multi-step reasoning problems.
2. Humanities Literature, philosophy, history, ethics. These questions often require cultural knowledge and nuanced understanding that goes beyond pure logic.
3. Social Sciences Psychology, sociology, economics, geography. These test understanding of human behavior and social systems.
4. Other (Professional and Applied) Law, medicine, business, education. Real-world professional knowledge that you’d need in specific careers.
What Good MMLU Scores Actually Mean
Here’s where it gets interesting. The benchmark reports accuracy as a percentage, but what do those numbers really tell us?
- 25% (Random chance): Since it’s multiple choice with 4 options, pure guessing gets you here
- 50% (High school graduate): This is roughly where an average high school student performs
- 70% (College graduate): Strong performance across most subjects
- 80%+ (Expert level): This is where top AI models are reaching today
When GPT-4 first hit around 86% on MMLU, it was a big deal. That’s better than most college graduates across this incredibly broad range of topics.
Why I Find MMLU Both Brilliant and Flawed
What I love about it:
- It’s comprehensive. No other benchmark tests knowledge this broadly
- It’s standardized. Every model gets the same questions under the same conditions
- It’s measurable. Clear scoring makes it easy to track progress
- It reflects real academic knowledge that matters
What concerns me:
- Multiple choice can be gamed. Sometimes you can eliminate wrong answers without knowing the right one
- It doesn’t test practical application. Knowing facts isn’t the same as using them effectively
- Cultural bias exists. Many questions reflect Western academic traditions
- It’s static. The questions don’t evolve, so models can potentially overfit
How AI Models Actually Tackle MMLU
This is where it gets technical but interesting. Modern language models approach MMLU through what researchers call “few-shot learning.” They’re given a few example questions and answers, then asked to solve new problems.
The best models use several strategies:
- Pattern recognition: Finding similar question types they’ve seen before
- Elimination: Ruling out obviously wrong answers
- Domain knowledge: Drawing on their training to access relevant facts
- Reasoning: Working through multi-step problems logically
But here’s the fascinating part - they often get questions wrong in very human-like ways. They might know advanced physics but miss a basic chemistry question. Or nail complex philosophy but struggle with elementary geography.
What MMLU Scores Tell Us About AI Progress
Tracking MMLU scores over time reveals something remarkable about AI development:
- 2020: GPT-3 scored around 43% - below high school level
- 2022: PaLM reached about 70% - college graduate level
- 2023: GPT-4 hit 86% - expert level in many domains
- 2024: Some models are pushing toward 90%
Current Benchmarks (July 2025)
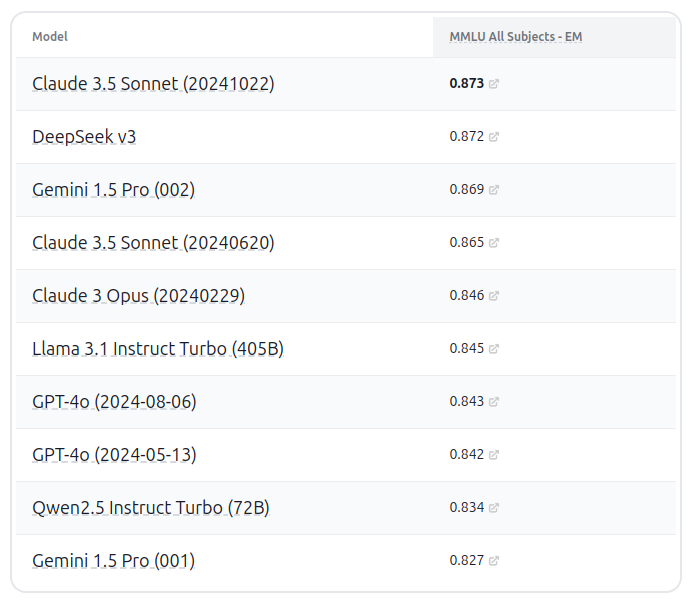
This rapid improvement is staggering. We went from below-human to expert-level performance in just a few years.
Beyond the Numbers: What MMLU Really Measures
But here’s what I’ve learned from studying MMLU closely - it’s not just measuring knowledge. It’s measuring something deeper about how AI systems process and apply information.
When a model scores 85% on MMLU, it’s demonstrating:
- Broad knowledge retention across dozens of fields
- Pattern matching across different question formats
- Transfer learning - applying knowledge from one domain to another
- Systematic reasoning - not just memorizing but thinking through problems
This is closer to what we call “general intelligence” than anything we could measure before.
The Future of MMLU and AI Evaluation
MMLU won’t be the final word on AI intelligence. Researchers are already working on more dynamic, practical benchmarks. But it’s given us something crucial - a standardized way to measure progress across the full spectrum of human knowledge.
As someone who’s watched this field evolve, I think MMLU represents a turning point. It’s the benchmark that helped us move from asking “Can AI do this specific task?” to “How broadly intelligent is AI becoming?”
And honestly? The progress we’re seeing is both exciting and a little mind-bending. We’re approaching a world where AI systems know more facts across more domains than most humans ever could. What we do with that capability - that’s the next chapter of this story.